GIST: The Google Algorithm Changing AI Training and SEO Strategy

In the modern technology landscape, we have long been told that "data is the new oil." However, the reality of 2024 and beyond is that we are no longer suffering from a lack of oil; we are drowning in a torrential flood of it. According to the sources, a single self-driving vehicle now generates approximately 80 terabytes of data daily from LiDAR and imaging devices. Academic datasets, once considered massive at the 1.2 million images of the original ImageNet, have scaled dramatically to over 5 billion images in datasets like LAION.
The crisis we face is not one of collection, but of selection. How do we pick the right data to train an AI model? How does a search engine pick the top 10 results out of 10 billion pages? When we select a small subset, we must guarantee that it is a "good representation" of the original dataset a concept the researchers call coverage.
I have spent the last week dissecting a landmark paper from a research team at Google titled GIST: Greedy Independent Set Thresholding for Max-Min Diversification with Submodular Utility."[1] This work addresses the MDMS problem (Max-Min Diversification with Monotone Submodular Utility) and introduces an algorithm that I believe will become the "precision filter" for the next decade of digital architecture.
This blog is a deep dive into the GIST algorithm, its mathematical soul, and its specific, transformative impact on AI training and search strategy.
What is Greedy Independent Set Thresholding? – Understanding MDMS
To understand GIST, you must first understand the problem it was born to solve: MDMS. At its heart, subset selection is a balancing act between two competing objectives.
1. The Utility Function ($g(S)$): The Law of Diminishing Returns
The first objective is to pick items that are "valuable or informative". The researchers use a monotone submodular function to model this.
- Monotone: This means "more is better." Adding a relevant item to your set should never decrease the total value.
- Submodular: This is the mathematical expression of the Law of Diminishing Returns. In technical terms, the "marginal gain" of an item decreases as the set grows.
If you are building a search result for "apple," the first article about the fruit is incredibly informative. The second article about the fruit is less so. By the time you reach the tenth article, the marginal gain is almost zero. A purely utility-driven algorithm, however, often ignores this "slowing down" of value and leads to redundancies where very similar points are chosen.
2. The Diversity Objective ($div(S)$): Max-Min "Social Distancing"
To counteract redundancy, GIST adds a diversification term: Max-Min Diversity. Unlike older systems that tried to increase the "average" variety (Max-Sum), Max-Min diversity looks at the two most similar items in your list and measures the gap between them.
How GIST Works (The "Social Distancing" Analogy)
GIST uses a concept called an Intersection Graph. Imagine every data point is a person in a room.
1. Set a "Distance Rule" (d): The algorithm picks a distance (e.g., "everyone must stay 6 feet apart").
2. Draw the "Conflict Lines": It draws a line between any two people who are closer than 6 feet. These are "conflicts".
3. Find an Independent Set: It tries to pick a group of people such that no two people are connected by a conflict line.
4. The Greedy Selection: To pick who stays in the room, it acts "greedily"—it always picks the person who adds the most "quality" first, as long as they aren't standing too close to someone already picked.
5. The "Sweep": GIST doesn't just try one "distance rule." It runs this process multiple times with different rules (e.g., 1 foot, 5 feet, 10 feet) and finally picks the shortlist that resulted in the highest overall score.
The goal is to ensure that the selected points are maximally separated. If you think of your data as people in a room, Max-Sum diversity wants everyone to be generally spread out. Max-Min diversity (GIST’s approach) demands that no two people stand closer than, say, six feet apart. If anyone breaks that rule, the set is penalized.
3. The "Knob" ($\lambda$): The Regularization Strength
The formula the researchers study is $f(S) = g(S) + \lambda \cdot div(S)$. Here, $\lambda$ (lambda) is described as a "knob" that controls the trade-off between quality and variety. It acts as a regularization strength. If you turn $\lambda$ up, the algorithm becomes a strict diversity enforcer, skipping high-quality items if they are even slightly redundant. If you turn it down, it prioritizes popularity and raw utility.
The GIST Algorithm – How the "Precision Filter" Works
The researchers prove that finding the perfect "best and most diverse" list is NP-hard it is mathematically impossible to solve perfectly in a reasonable timeframe. Simple greedy algorithms fail here; they can have an "arbitrarily poor performance" because the diversity term is non-monotone (it can go down as you add items).
GIST (Greedy Independent Set Thresholding) solves this by using a "sweep" technique.
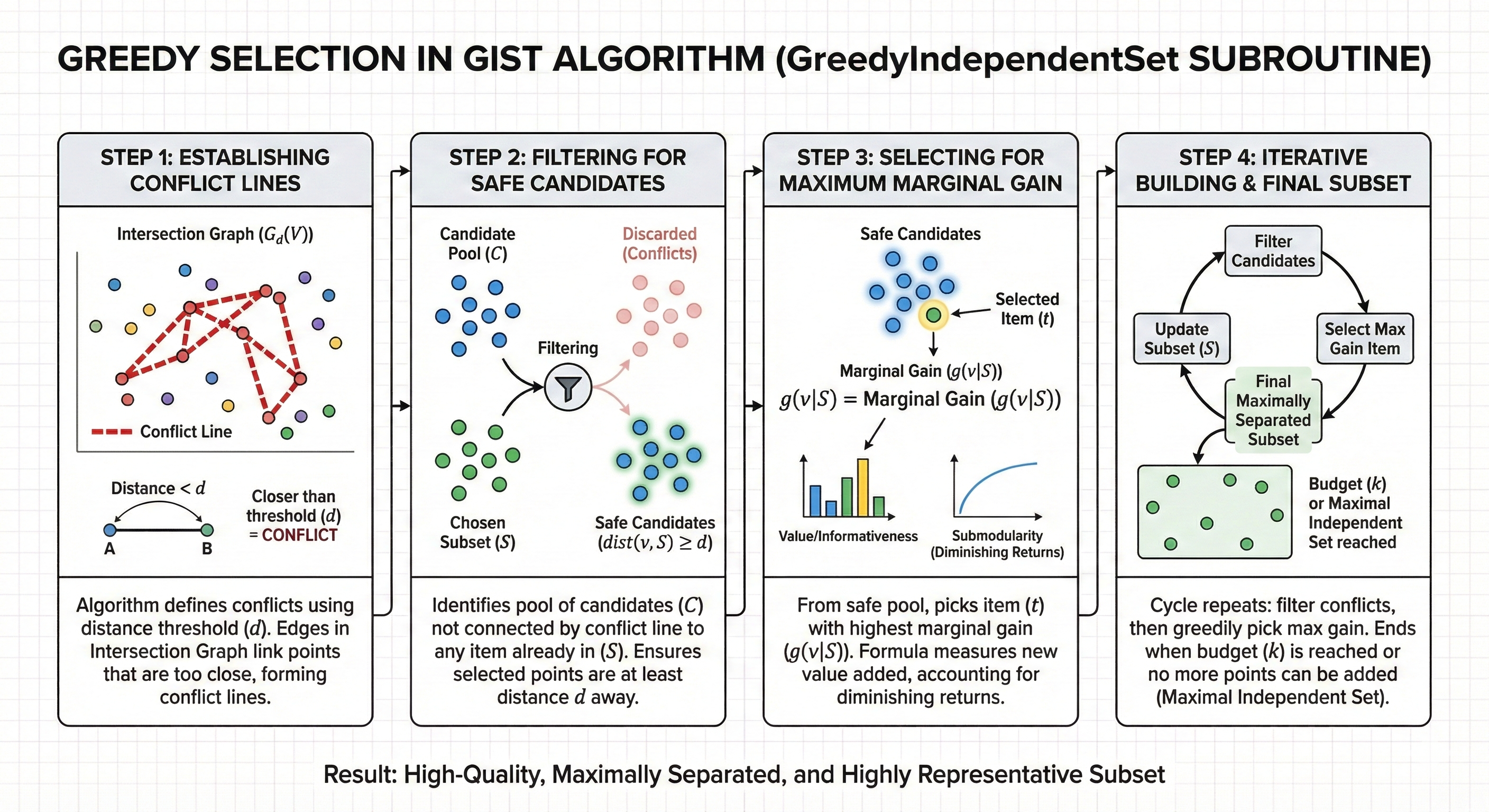
The Intersection Graph and "Conflict Zones"
The algorithm works by looking at an Intersection Graph ($G_d(V)$). Imagine every data point is a node. If two points are closer than a certain distance threshold ($d$), the algorithm draws a line a "conflict" between them.
- An Independent Set is a group of points where no two points have a line between them.
- This ensures that every item in your shortlist is "maximally separated" by at least distance $d$.
The "GreedyIndependentSet" Subroutine
For a given distance threshold $d$, GIST runs a subroutine:
- It looks at all available items that are at least distance $d$ away from the items already picked.
- From that "safe" pool, it picks the item with the highest marginal gain ($g(v|S)$).
- It repeats this until the budget ($k$) is reached or no more "safe" items exist.
The Sweep
Because we don't know the "perfect" distance threshold, GIST doesn't just guess. it sweeps over multiple thresholds ($D$). It tests a range of distances from very tight to very wide and returns the final shortlist that produced the highest overall objective value ($f(S)$).
Impact #1 – AI Model Training
The most powerful practical application demonstrated in the paper is in Data Sampling for AI. As models grow, training on 100% of a dataset becomes prohibitively expensive. We need "single-shot" subsets that are small but incredibly "smart."
The ImageNet Trials
The researchers tested GIST on the ImageNet dataset (1.3 million images) to train a ResNet-56 model. They compared GIST against the current gold standards: Margin Sampling (which picks the "hardest" examples) and k-center (which picks the most "diverse" examples).
The Performance Gap: The results showed that GIST with margin or submodular utility was superior to all baselines.
- Low Budgets (30%): GIST reached 67.24% accuracy, beating $k$-center's 66.71%.
- High Budgets (90%): GIST hit 76.12% accuracy, while standard margin sampling only reached 75.11%.
Why This Matters for AI Developers
- Downsampling without Accuracy Loss: GIST allows you to throw away 10% or 20% of your data and actually improve your model’s accuracy. By optimizing for a "blend of utility and diversity," GIST ensures the training set is a more representative sample of the original dataset.
- Computational Efficiency: Training a model takes hours or days. The GIST subset selection process, however, is "extremely fast (nearly negligible)," taking only 3–4 minutes on average.
- Scalability: For organizations dealing with billions of data points, GIST can be paired with distributed submodular algorithms to handle massive scale efficiently.
Impact #2 – Search Ranking & SEO
The sources explicitly connect this work to the design of ranking systems for search engines. The paper's actual contribution is a mathematical refinement of earlier search principles.
From Max-Sum to Max-Min
Earlier work by Gollapudi and Sharma used a "Max-Sum" approach to diversify search results. The problem with Max-Sum is that it prioritizes the average variety of a page. You could have a page with a high average variety that still contains two nearly identical results that annoy the user.
GIST’s Max-Min approach ensures that every single result is "maximally separated" from every other result. This leads to subsets that are "less redundant and more representative".
The SEO Strategy Shift: Beyond "Consensus Content"
If you are a publisher or a brand, the GIST logic fundamentally changes how you should approach content creation.
-
The Conflict Zone: In the GIST framework, if your content is too similar to a top-ranking competitor, you are "connected" by a conflict line in the intersection graph. In a "greedy" selection process, the algorithm will pick the item with the highest utility and discard the redundant neighbor.
-
Optimizing for Marginal Gain: You cannot win by simply being "better" (higher utility $g(S)$). You must be orthogonally different. You need to provide a high marginal gain relative to the existing top results.
Practical SEO Implementation: Instead of rewriting the top result, you must identify the "Missing Node" in the knowledge space. If the top result covers the "price and features" of a product, your content must cover the "integration challenges" or "legal compliance." By increasing your semantic distance from the leader, you exit their "conflict zone" and become a viable candidate for the algorithm's diverse shortlist.
The Business Reality – Unit Economics and the "Lambda Trap"
Why is a company like Google investing so heavily in MDMS and GIST? The answer lies in Unit Economics and Compute Efficiency.
The Cost of Redundancy
As we move into the era of Large Language Models (LLMs), processing redundant information is a massive waste of resources. The sources note that subset selection is critical for designing pretraining sets for LLMs. By using GIST to prune redundant data before it ever hits a GPU, companies can save millions in compute costs while maintaining or even improving model performance.
The "Lambda Trap" – A Warning for Decision Makers
While diversity is a "reward," the paper contains a subtle warning in its "NO case" mathematical proof.
- If you set the diversity strength ($\lambda$) too high, the algorithm focuses so much on distance that it "forgos most of the potential value" of the quality data.
- In a search context, this means that if you prioritize variety too much, you end up showing a user "unique" results that are completely irrelevant to their query.
For business owners, the goal is to find the "Goldilocks Zone". You want to be different enough to avoid being filtered as a redundancy, but you must remain high-utility enough that the algorithm doesn't "forgo" your value during the greedy selection process.
How to Implement GIST Principles Today
You don’t need to be a mathematician to apply these insights to your offerings. Here is a practical protocol for competing in a GIST-filtered world:
1. Calculate Semantic Similarity: Use LLMs to generate embeddings for your content and your top three competitors. If the cosine distance (the metric used in the ImageNet trials) is too small (e.g., similarity >85%), you are in the "Conflict Zone." 2. Audit for Submodularity: Look at your product line or content feed. Does your fifth item add marginal gain, or is it just another version of your first item? If you aren't adding unique value ($g(v|S)$), the algorithm will eventually prune you. 3. Target the "Max-Min" Gap: Look for the two most similar results currently on the first page of Google. Position your content to be the "divider" between them provide the perspective that makes the existing results look redundant by comparison. 4. Leverage Fast Sampling: If you are training your own internal AI models for customer behavior or recommendation systems, stop using random sampling. Use a GIST-margin approach. It will take only 3-4 minutes to run but could increase your model's accuracy by a full percentage point.
Conclusion: From Brute Force to Precision
The GIST algorithm signals a clear shift in how digital systems choose and use data. We are moving from brute-force collection to representative precision, where selecting the right data matters more than collecting everything.
With a proven 1/2-approximation guarantee, platforms can now prioritize high-quality, diverse, and representative signals. That changes how AI models are trained, how search surfaces results, and how content earns visibility. For brands and publishers, distinct, high-signal content is now a technical growth lever, not just a branding choice.
At GrowthJockey, we continuously track AI, search, and advertising intelligence trends and convert them into practical growth frameworks for businesses. From AI-led marketing systems to precision content and performance strategies, we help ventures stay ahead of algorithm shifts and market changes.
If you want your business to grow with what’s next instead of reacting late, build with a team that operates at the edge of AI and digital commerce. Let GrowthJockey help you turn precision into scale.
FAQs
1. Why is Google changing how it picks top results again?
We are facing a "selection crisis" drowning in data like the 80TB generated daily by a single self-driving car. I view this update as the necessary shift from brute force collection to "Representative Precision." It ensures we get distinct, high-value answers rather than ten links saying the exact same thing.
2. What actually is 'GIST' and why does it matter?
Think of GIST as a mathematical "precision filter" for the AI age. It matters because it enforces a "social distancing" rule on data guaranteeing that the results we see are not just accurate, but "maximally separated" and unique from one another.
3. I wrote a better article than the #1 result, why am I still not ranking?
You are likely trapped in the "Conflict Zone." In this framework, simply being "better" isn't enough if you are semantically too similar to the leader; the algorithm views you as "redundant" and filters you out. To win, I believe you must be "orthogonally different" and provide a unique angle they missed.
4. My traffic dropped recently. What could be the reason?
Your content may have been flagged as "redundant data." If your semantic similarity to a competitor is too high, the algorithm’s "greedy selection" likely discarded you to maximize diversity. You need to audit for "Marginal Gain" if you aren't adding unique value, the algorithm is now designed to prune you.








