Knowledge-Based Agent in Artificial Intelligence: Architecture & Components

The blog defines a knowledge-based agent in AI by contrasting the Declarative and Procedural Approaches and highlighting the role of the Inference Engine. It benchmarks these agents against reactive, reflex, goal-based, utility-based, and learning agents. It unpacks core components, the knowledge base, inference engine, and Tell-Ask-Perform cycle, and explores symbolic and hybrid representation methods. Find a four-phase roadmap that recommends modern tools for practical implementation.
Every day, teams drown in fragmented information, brittle scripts, and inconsistent decisions as business rules change.
That’s why a knowledge-based agent in AI exists: it blends a declarative approach, separating “what” it knows from an inference engine that applies logic to facts and rules, so you can update knowledge without rewriting code. Unlike simple AI agents that only react, these systems have lots of facts and rules stored.
In this blog, you’ll learn how these agents work, see how they compare to other similar agents, and follow a step-by-step framework to build your first knowledge-based agent in AI.
What Are Knowledge-Based Agents in AI ?
A knowledge-based agent in AI is like a smart helper that uses what it knows (facts) and a set of rules to figure things out and make decisions. Instead of just reacting, it actually thinks through problems using logic and reasoning kind of like how we act when we use what we’ve learned to solve a puzzle. It stores knowledge, updates it when it learns something new, and then uses that to decide what to do next.
They're commonly deployed in chatbots, healthcare diagnostic tools, and automated advisory systems. By analyzing accumulated facts, established protocols, and historical data patterns, these agents can deliver informed solutions.
Since it relies on a declarative approach - separating the “what” (knowledge) from the “how” (reasoning), developers can update or expand its repository of statements without ever touching the reasoning mechanism.
So, how is it any different from reactive engines?
Reactive agents simply map sensory inputs to actions (if you see heat, you turn on the fan). Knowledge-based agents go further: they interpret raw data, apply rules or logic, and plan multi-step responses. In other words, they bridge the gap between isolated facts and meaningful, goal-driven behaviour.
Ok, what about reflex agents? Or learning agents?
Where reflex agents react immediately to a stimulus with a fixed condition (action rule), knowledge-based agents look up relevant facts, apply logic, and then act.
As for learning agents, they adapt their behaviour over time based on experience but don’t necessarily maintain an explicit, inspectable store of domain knowledge.
A knowledge-based agent sits between these two: it isn’t locked into hard-coded reflexes, nor does it rely solely on opaque learned weights. Instead, it combines a persistent knowledge repository with a reasoning engine, and only gains true adaptability when paired with a learning component that updates its knowledge base.
Here’s a side-by-side comparison for better understanding how knowledge-based agents compare to agentic models and AI agents, and clarify where each excels.
| Feature | Knowledge-Based Agent in AI | Reactive Agents | Goal-Based Agents | Utility-Based Agents |
|---|---|---|---|---|
| Knowledge Representation | Explicit knowledge base with facts and rules | Minimal internal state | Simple goal representation | Preference functions |
| Decision Process | Inference engine reasoning | Direct stimulus-response mapping | Planning towards goals | Utility maximisation |
| Adaptability | Updates through knowledge base modifications | Fixed response patterns | Goal adjustments | Utility function updates |
| Problem Solving | Logical deduction and inference | Pattern matching | Search algorithms | Optimisation techniques |
| Use Cases | Expert systems, diagnosis tools | Simple control systems | Robot navigation | Economic modelling |
Importance in the real world
In modern AI pipelines, a knowledge-based agent in AI can validate ML outputs, enforce domain rules, and add crucial context. This hybrid approach combines learning’s adaptability with rule-based rigor to power reliable expert systems, decision-support tools, and advanced virtual assistants.
Core architecture: How knowledge-based agents work
Choosing between a declarative approach and a procedural approach will shape how you update rules versus code. Here’s a breakdown of the fundamental components that make knowledge-based agents function effectively:
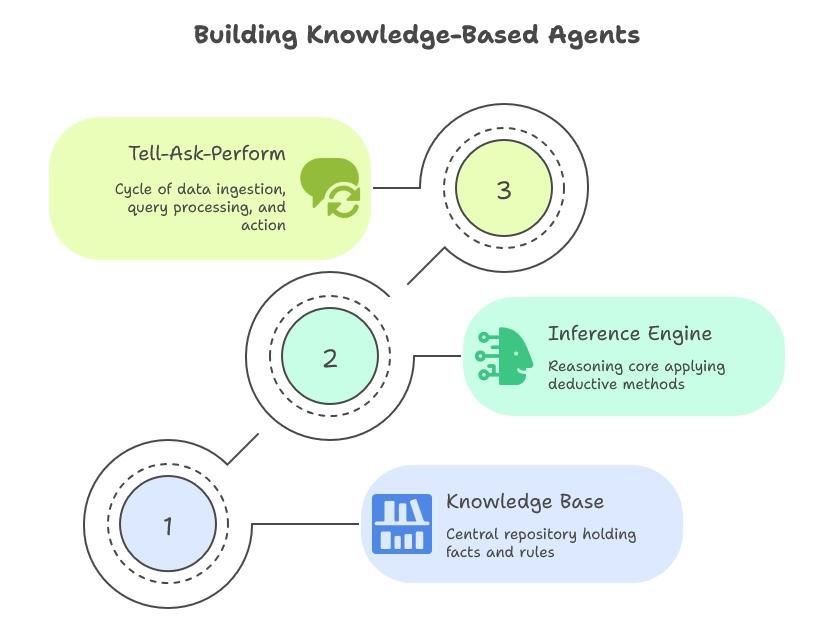
The knowledge base: Your agent's brain
This central repository holds facts, rules, and ontologies that define the agent’s domain. It can use structured formats (semantic graphs, relational tables) or indexed unstructured text for retrieval.
Updates, version control, and consistency checks keep the knowledge reliable with every new information.
Inference engine: The reasoning powerhouse
Acting as the reasoning core, it applies forward chaining to derive new facts and backward chaining to verify goals against existing knowledge.
It combines deductive, inductive, and abductive methods, and uses conflict-resolution strategies when multiple rules apply, to reach coherent conclusions.
Tell-Ask-Perform cycle
-
TELL: The agent ingests and integrates new data
-
ASK: It processes queries and retrieves relevant knowledge
-
PERFORM: It turns inferences into concrete actions or responses, completing the loop between reasoning and behaviour
Pro tip: Version-control your knowledge base. Treat rules and ontologies like code: store them in Git-friendly formats (JSON-LD, YAML, or Turtle) so you can track changes, review updates, and roll back safely.
Logic and rule-based agent types
Knowledge-based agents differ in how they represent and manipulate their knowledge. Below are two major paradigms: purely symbolic methods and modern hybrids that power today’s expert systems and decision engines.
1. Symbolic representation methods
- Propositional and First-Order Logic
From simple true/false statements to objects, properties, variables, and quantifiers, these logics let agents encode domain facts and relationships with mathematical rigour.
- Production Rules and Semantic Networks
“If…then” rules provide modular knowledge blocks, while semantic networks link concepts in graph structures for flexible traversal and inference. By contrast, a procedural approach embeds decision paths in code, trading flexibility for speed.
- Ontologies and Knowledge Graphs
Rich, hierarchical schemas define entity types, their attributes, and interconnections. Knowledge graphs layer data relationships directly atop ontologies to support complex queries and reasoning.
2. Modern hybrid approaches
- Symbolic + Machine Learning
Agents can use ML to extract patterns or generate candidate insights, then apply symbolic rules to validate, refine, or explain those outputs.
- Vector embeddings for knowledge
Continuous embeddings transform words, entities, or entire documents into numerical vectors, allowing for similarity-based retrieval and analogical reasoning.
- Integration with Large Language Models
Deep LMs supply broad, contextual knowledge and natural-language understanding, which hybrid systems can ground with explicit rules or ontologies for more reliable, explainable behaviour.
Levels of knowledge-based agent sophistication
Knowledge-based agents in AI vary in sophistication depending on their reasoning abilities.
-
Simple agents handle basic fact-checking and rule application, while intermediate agents use probabilistic reasoning to deal with uncertainty and incomplete information.
-
Advanced systems feature complex inference mechanisms, including backward and forward chaining processes. They can handle temporal reasoning and understand how knowledge changes over time.
-
The highest-level agents integrate machine learning to automatically acquire new knowledge from experience.
simple → probabilistic → temporal → ML-augmented
As autonomous AI systems mature, knowledge-based agents are learning to reason with context, uncertainty, and time.
Building your first knowledge-based agent: A step-by-step checklist
Now that you know what your teams need to build a knowledge-based agent, here’s how to create your first knowledge-based agent in AI from scratch:
Pro tip: Jump-start with standard ontologies. Don’t build from scratch; use existing vocabularies (e.g., SNOMED CT for healthcare) to seed your knowledge base and avoid reinventing core domain concepts.
Phase 1: Domain analysis and scope definition
-
Begin by scoping the problem: identify stakeholders, use cases, and operational constraints.
-
Then translate business goals into measurable agent objectives like response accuracy, latency, and coverage.
-
Assess what knowledge the agent needs: catalogue key concepts, decision points, and data sources, and map these to success metrics (precision, recall, user satisfaction)
Phase 2: Knowledge base design and population
-
Choose a representation that fits your domain: facts & rules in a production‐rule engine, ontologies in OWL/RDF, or hybrid vector stores
-
Collect data via manual elicitation from experts, text‐mining, or automated crawlers
-
Then extract and normalise entities, relations, and rules.
-
Rigorously validate consistency and completeness, using schema validators or ontology reasoners (e.g., Protégé)
Phase 3: Inference engine implementation
-
Select reasoning algorithms aligned to your use cases: forward/backward chaining for rule‐driven logic, or hybrid engines that integrate probabilistic inference.
-
Build or configure a rule‐execution framework (e.g., Drools, CLIPS) and profile hot spots.
-
Optimise performance through indexed rule sets, incremental reasoning, or precompiled inference trees.
Phase 4: Integration and testing
-
Embed your agent into the target environment: API, chatbot, or backend service using adapter patterns to decouple interfaces.
-
Employ structured V&V: unit tests for rule validation, scenario‐based tests for decision quality, and exploratory testing for edge cases.
-
Finally, establish monitoring (log inference traces, track key metrics) and maintenance workflows to update knowledge as your domain evolves.
Modern development tools and frameworks
Building a knowledge-based agent is easier today than ever. You can pick tools that fit your needs. Here’s a quick guide to the main options.
Pro tip: Containerise both your rule engine and graph store. Use Docker Compose (or Kubernetes) to spin up CLIPS/Drools alongside Neo4j or Blazegraph.
Symbolic reasoning frameworks
-
Prolog is a classic logic tool where you encode facts and rules in plain code.
-
If you’d rather work visually, CLIPS and Drools let you build and test “if…then” rules without much coding.
-
For rich data links, Neo4j or Blazegraph let you store facts as graphs and ask simple queries with Cypher or SPARQL.
Hybrid AI platforms
-
If you want your agent to learn from data, go for TensorFlow and PyTorch. They plug right into your system.
-
LangChain and LlamaIndex make it easy to add large language models for smart text understanding.
Pro tip: Mix learned models with your rules so the agent can handle both pattern-finding and clear logic.
Enterprise-ready solutions
-
When you need scale, Docker and Kubernetes keep things running smoothly.
-
You can secure data with role-based access or tools like Open Policy Agent.
-
Finally, set up Prometheus or Grafana to watch key metrics and alert you if anything breaks.
Use machine learning to enhance knowledge-based agents
Machine learning automates the discovery of rules and patterns from data, reducing the need for manual rule encoding.
Research on AI reasoning[1] and deep learning found that when combined with a declarative knowledge base, ML handles fuzzy, probabilistic reasoning, classifying inputs or ranking options, while the symbolic layer enforces hard constraints and logical consistency.
Vector embeddings power similarity-based retrieval, letting agents match new queries to related concepts even without exact keyword overlaps[2]. Hybrid neuro-symbolic systems, explored in recent surveys, integrate deep learning with logic engines to build applications from medical-diagnosis assistants to adaptive customer-service bots
Knowledge-based agents real-world case study
IBM Watson represents a prominent knowledge-based agent in a success story in healthcare. Memorial Sloan Kettering Cancer Center partnered with IBM to create an oncology decision support system. Watson analysed vast medical literature, patient records, and treatment guidelines to assist oncologists.
The system reviewed thousands of medical journals and clinical trial data to offer evidence-based treatment advice. Watson's inference engine assessed multiple treatment options, considering patient-specific factors. This knowledge-based agent example showed how AI can assist medical decisions with thorough knowledge analysis.
Future of knowledge-based agents
Recent studies[3] indicate the AI systems market will reach $17 billion in India by 2027, with healthcare and finance leading the way. The approach to representing knowledge is becoming more flexible and aware of context.
These advances are aligned with broader trends in agentic AI frameworks, which are blending symbolic reasoning with modern machine learning.
In the future, knowledge-based AI agents will automatically pull information from unstructured sources like documents and videos. They will be able to explain their reasoning, making things clear for users. Integration with quantum computing could make processing large knowledge bases much faster and more complex.
Summing up on knowledge-based agents
A knowledge-based agent in AI is more than a reactive program; it stores facts and rules in a knowledge base, uses an inference engine to reason about them, and updates its behaviour via a declarative approach rather than hard-coded procedures.
As technology improves, these systems will get even better, combining machine learning with traditional reasoning to create smarter applications.
For businesses wanting to implement these systems, partnering with business accelerators like GrowthJockey can speed up your AI journey.
FAQs on knowledge-based agents
1. What is a knowledge-based agent?
A knowledge-based agent in AI is an intelligent system that uses stored facts and rules to make decisions through logical inference and reasoning.
2. What is a knowledge-based agent example?
A knowledge-based agent example is IBM Watson’s oncology decision-support system, which ingests massive medical literature, patient histories, and clinical guidelines into its knowledge base.
The system applies inference rules to suggest diagnosis options and treatment plans, assisting clinicians with evidence-based recommendations.
3. What is the difference between a goal-based agent and knowledge-based agent?
While goal-based agents prioritise achieving specific objectives by planning action sequences toward defined targets.
Knowledge-based agents emphasise logical inference over a knowledge base with facts and rules. They reason, update their knowledge, and adapt responses instead of following preset goal plans.
4. What is a learning-based agent?
A learning-based agent improves its behaviour over time by observing outcomes and adjusting its strategies through algorithms like reinforcement learning and supervised learning.
Instead of relying solely on rules, such agents gain new knowledge from data, refining decision policies autonomously.








